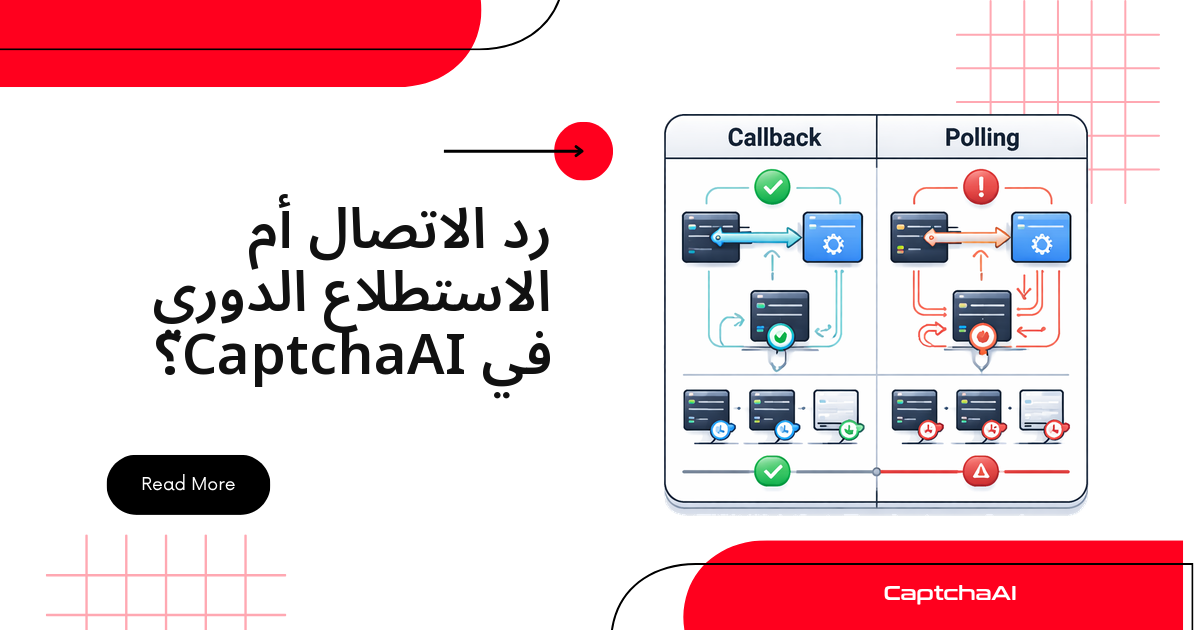
يتكامل HTTPX مع CaptchaAI عبر مسار من ثلاث خطوات: تُرسل بيانات اختبار CAPTCHA إلى نقطة النهاية in.php، تستطلع النتيجة دورياً من res.php، ثم تُمرّر التوكن الناتج إلى النموذج الذي تعمل عليه. ما يميّز HTTPX عن بقية عملاء HTTP في Python أنه يقدّم الواجهتين المتزامنة وغير المتزامنة معاً، مع دعم HTTP/2 — وهو ما يجعله مناسباً لحل عشرات اختبارات reCAPTCHA على التوازي دون تعقيد إضافي. في هذا الدليل نبني عميلاً كاملاً بالنمطين ونربطه بحسابك على CaptchaAI.
لماذا HTTPX تحديداً لحل CAPTCHA؟
معظم أكواد حل CAPTCHA في Python تعتمد على مكتبة requests، وهي خيار سليم للسكربتات القصيرة. لكن عند الحاجة إلى إرسال عدد كبير من الطلبات في وقت واحد — كمراقبة الأسعار أو اختبارات الجودة على نطاق واسع — يتحوّل النموذج المتزامن التقليدي إلى عنق زجاجة، إذ ينتظر كل طلب انتهاء سابقه.
يعالج HTTPX هذه المشكلة عبر ثلاث مزايا:
- واجهة برمجة شبه مطابقة لمكتبة requests، فالترحيل إليها لا يتطلب إعادة كتابة كبيرة.
- عميل غير متزامن مبني على asyncio يتيح تشغيل مئات عمليات الحل بالتوازي.
- دعم HTTP/2 الذي يمرّر عدة طلبات عبر اتصال واحد، فيقلّل زمن الانتظار عند الإرسال والاستطلاع المتكرر.
بعبارة أخرى، تكتب الكود مرة واحدة وتقرّر لاحقاً هل تشغّله بنمط متزامن بسيط أم غير متزامن عالي التوازي.
المتطلبات قبل البدء
قبل كتابة أي سطر، تأكّد من توفّر البيئة التالية. ستحتاج تحديداً إلى مفتاح CaptchaAI API من لوحة التحكم، فهو ما يربط طلباتك برصيدك:
| المتطلب | التفاصيل |
|---|---|
| Python | 3.8+ |
| httpx | 0.24+ |
| مفتاح CaptchaAI API | احصل عليه من هنا |
pip install httpx
بناء العميل المتزامن
العميل المتزامن مناسب للسكربتات المتسلسلة واختبارات الجودة البسيطة. الفكرة أن تغلّف نقطتي النهاية in.php وres.php داخل صنف واحد يتولّى الإرسال والاستطلاع نيابةً عنك.
يسير العمل على النحو التالي:
- تُرسل بيانات المهمة إلى
in.php، فتردّ الخدمة بالشكلOK|task_idعند القبول. - تستطلع
res.phpكل خمس ثوانٍ؛ فطالما ظهرت الاستجابةCAPCHA_NOT_READYيعني أن الحل لم يكتمل بعد. - عند اكتمال الحل تعود الاستجابة بالشكل
OK|token، فتستخرج التوكن وتستخدمه.
ينفّذ الصنف التالي هذا المسار كاملاً، ويضيف دالة get_balance لقراءة الرصيد ومهلة انتهاء افتراضية مقدارها خمس دقائق:
import httpx
import time
import os
class CaptchaAISync:
def __init__(self, api_key):
self.api_key = api_key
self.base_url = "https://ocr.captchaai.com"
self.client = httpx.Client(timeout=30)
def solve(self, params, timeout=300):
params["key"] = self.api_key
# Submit
resp = self.client.get(f"{self.base_url}/in.php", params=params)
text = resp.text
if not text.startswith("OK|"):
raise Exception(f"Submit failed: {text}")
task_id = text.split("|")[1]
# Poll
deadline = time.time() + timeout
poll_params = {"key": self.api_key, "action": "get", "id": task_id}
while time.time() < deadline:
time.sleep(5)
result = self.client.get(
f"{self.base_url}/res.php", params=poll_params
)
if result.text == "CAPCHA_NOT_READY":
continue
if result.text.startswith("OK|"):
return result.text.split("|", 1)[1]
raise Exception(f"Solve failed: {result.text}")
raise TimeoutError(f"Task {task_id} timed out")
def get_balance(self):
resp = self.client.get(f"{self.base_url}/res.php", params={
"key": self.api_key, "action": "getbalance"
})
return float(resp.text)
def close(self):
self.client.close()
# Usage
solver = CaptchaAISync(os.environ["CAPTCHAAI_API_KEY"])
token = solver.solve({
"method": "userrecaptcha",
"googlekey": "6Le-wvkS...",
"pageurl": "https://example.com",
})
print(f"Token: {token[:50]}...")
solver.close()
بناء العميل غير المتزامن
عندما يكون لديك عدد كبير من اختبارات CAPTCHA لحلّها في آنٍ واحد، يصنع العميل غير المتزامن الفارق الحقيقي. بدل انتظار كل حل على حدة، تُطلق عمليات الإرسال والاستطلاع كلها ضمن حلقة أحداث asyncio واحدة، ثم تجمع النتائج عبر asyncio.gather.
المنطق الداخلي مطابق للنسخة المتزامنة — إرسال، ثم استطلاع دوري، ثم إعادة التوكن — لكن كل استدعاء شبكي يصبح await، فلا يحجب بقية المهام. لاحظ استخدام return_exceptions=True كي لا يُسقط فشلُ صفحة واحدة معالجةَ بقية الصفحات:
import httpx
import asyncio
import os
class CaptchaAIAsync:
def __init__(self, api_key):
self.api_key = api_key
self.base_url = "https://ocr.captchaai.com"
self.client = httpx.AsyncClient(timeout=30)
async def solve(self, params, timeout=300):
params["key"] = self.api_key
# Submit
resp = await self.client.get(
f"{self.base_url}/in.php", params=params
)
text = resp.text
if not text.startswith("OK|"):
raise Exception(f"Submit failed: {text}")
task_id = text.split("|")[1]
# Poll
deadline = asyncio.get_event_loop().time() + timeout
poll_params = {"key": self.api_key, "action": "get", "id": task_id}
while asyncio.get_event_loop().time() < deadline:
await asyncio.sleep(5)
result = await self.client.get(
f"{self.base_url}/res.php", params=poll_params
)
if result.text == "CAPCHA_NOT_READY":
continue
if result.text.startswith("OK|"):
return result.text.split("|", 1)[1]
raise Exception(f"Solve failed: {result.text}")
raise TimeoutError(f"Task {task_id} timed out")
async def get_balance(self):
resp = await self.client.get(f"{self.base_url}/res.php", params={
"key": self.api_key, "action": "getbalance"
})
return float(resp.text)
async def close(self):
await self.client.aclose()
# Usage
async def main():
solver = CaptchaAIAsync(os.environ["CAPTCHAAI_API_KEY"])
# Solve multiple concurrently
tasks = [
solver.solve({
"method": "userrecaptcha",
"googlekey": "6Le-wvkS...",
"pageurl": f"https://example.com/page{i}",
})
for i in range(5)
]
results = await asyncio.gather(*tasks, return_exceptions=True)
for i, r in enumerate(results):
if isinstance(r, Exception):
print(f"Page {i}: FAILED - {r}")
else:
print(f"Page {i}: solved ({len(r)} chars)")
await solver.close()
asyncio.run(main())
تسريع الأداء عبر HTTP/2
لأن حل CAPTCHA يبدأ بطلب إرسال واحد يتبعه عدة طلبات استطلاع، فإن كل اتصال جديد يضيف زمناً ضائعاً في مصافحة TCP وTLS. يتيح HTTP/2 تمرير هذه الطلبات كلها عبر اتصال واحد مُعاد استخدامه. فعّل الدعم بتثبيت الحزمة الإضافية:
pip install httpx[http2]
ثم أنشئ العميل مع تفعيل الخيار http2=True:
client = httpx.AsyncClient(http2=True, timeout=30)
يمرّر HTTP/2 عدة طلبات عبر اتصال واحد، فيتحسّن الأداء بوضوح عند إرسال واستطلاع عدد كبير من اختبارات CAPTCHA في وقت متقارب.
ربط التزامن بعدد الـ threads في خطتك
هنا نقطة يغفل عنها كثيرون: عدد الطلبات المتزامنة التي تشغّلها عبر asyncio.gather ينبغي أن يتوافق مع عدد الـ threads في خطتك على CaptchaAI. فالفوترة في CaptchaAI تقوم على عدد الـ threads المتزامنة لا على عدد عمليات الحل، وكل خطة تتيح عمليات حل غير محدودة خلال الشهر.
لنأخذ سيناريو واقعياً: فريق في القاهرة يبني أداة لمراقبة أسعار المنتجات عبر عدّة منصّات تجارة إلكترونية إقليمية، وتظهر بعض هذه المنصّات اختبار reCAPTCHA عند تكرار الطلبات. لو صمّم الفريق سكربتاً يطلق نحو 40 عملية حل بالتوازي، فإنه يحتاج خطة تغطّي هذا العدد من الـ threads.
على سبيل التوجيه فقط، تبدأ خطة BASIC من $15 شهرياً مع 5 threads وتناسب التجارب الصغيرة، بينما توفّر خطة ADVANCE بسعر $90 شهرياً نحو 50 thread تكفي لسيناريو المراقبة أعلاه. القاعدة العملية بسيطة: اجعل حدّ التزامن في الكود مساوياً لعدد الـ threads المتاح أو أقل منه قليلاً، تفادياً لطلبات تنتظر دورها. الأسعار بالدولار الأمريكي، ويُنصح دائماً بمراجعة صفحة الأسعار الرسمية قبل الاعتماد.
مثال عملي: استخراج صفحة محمية بـ CAPTCHA
يجمع المثال التالي كل ما سبق في سيناريو واقعي: نجلب الصفحة، نبحث عن data-sitekey في محتواها، نحلّ اختبار reCAPTCHA عبر CaptchaAI، ثم نعيد إرسال النموذج ومعه التوكن في الحقل g-recaptcha-response. وإن لم تحتوِ الصفحة على مفتاح موقع، نعيد المحتوى كما هو:
import httpx
import re
import os
async def scrape_with_captcha(url, solver):
async with httpx.AsyncClient() as client:
# Fetch page
resp = await client.get(url)
html = resp.text
# Check for reCAPTCHA
match = re.search(
r'data-sitekey=["\']([A-Za-z0-9_-]+)["\']', html
)
if not match:
return html
site_key = match.group(1)
token = await solver.solve({
"method": "userrecaptcha",
"googlekey": site_key,
"pageurl": url,
})
# Submit form with token
resp = await client.post(url, data={
"g-recaptcha-response": token,
})
return resp.text
async def main():
solver = CaptchaAIAsync(os.environ["CAPTCHAAI_API_KEY"])
content = await scrape_with_captcha("https://example.com", solver)
print(f"Got {len(content)} chars")
await solver.close()
asyncio.run(main())
httpx مقابل requests مقابل aiohttp
لاختيار المكتبة الأنسب لسير عملك في حل CAPTCHA، يوضّح الجدول التالي الفروق الرئيسية بين الخيارات الثلاثة:
| الميزة | httpx (متزامن) | httpx (غير متزامن) | requests | aiohttp |
|---|---|---|---|---|
| الدعم غير المتزامن | ❌ | ✅ | ❌ | ✅ |
| HTTP/2 | ✅ | ✅ | ❌ | ❌ |
| تجميع الاتصالات | ✅ | ✅ | ✅ | ✅ |
| توافق الواجهة | شبيه بـ requests | شبيه بـ requests | — | مختلف |
| الأفضل لـ | بديل مباشر | كود غير متزامن حديث | سكربتات سريعة | تزامن عالٍ |
الأسئلة الشائعة
متى أفضّل httpx على requests في مشروع حل CAPTCHA؟
إن كنت تبدأ مشروعاً جديداً أو تتوقّع نموّاً في عدد الطلبات المتزامنة، فـ httpx هو الخيار الأنسب لأنه يمنحك النمطين المتزامن وغير المتزامن معاً. أما الكود القائم على requests فترحيله سهل: الواجهة شبه متطابقة، وغالباً يكفي تغيير الاستيراد وإنشاء العميل.
كم عدد الطلبات المتزامنة التي يمكنني تشغيلها؟
الحدّ الأعلى العملي هو عدد الـ threads في خطتك على CaptchaAI. إذا أطلقت عبر asyncio.gather طلبات أكثر من الـ threads المتاحة، فستنتظر الطلبات الزائدة دورها بدل أن تُعالَج فوراً. اضبط حدّ التزامن في الكود ليطابق خطتك.
كيف أتعامل مع الاستجابة CAPCHA_NOT_READY والمهلات الطويلة؟
الاستجابة CAPCHA_NOT_READY طبيعية وتعني أن الحل ما زال قيد المعالجة، لذا يواصل الكود الاستطلاع كل خمس ثوانٍ. حدّد مهلة انتهاء منطقية (خمس دقائق افتراضياً في الأمثلة أعلاه)، وعند تجاوزها يُطلق الكود TimeoutError لتعيد المحاولة أو تسجّل الخطأ.
أين أخزّن مفتاح الـ API بأمان؟
لا تكتب المفتاح داخل الكود مباشرة. الأمثلة هنا تقرؤه من متغيّر بيئة عبر os.environ، وهي الممارسة المُوصى بها في الإنتاج. استخدم متغيّرات البيئة أو مدير أسرار مخصّصاً، ولا تُضمّن المفتاح في مستودع Git.
هل يعمل httpx مع Scrapy أو FastAPI؟
مع FastAPI نعم ومباشرة، فكلاهما مبني على asyncio. أما Scrapy فيعتمد على حلقة أحداث Twisted، لذا استخدم httpx داخل سكربتات مستقلة أو ضمن أطر غير متزامنة، بدل دمجه مباشرة في Scrapy.